疯狂补票博客ing
Lab5涉及到了页错误机制的一个应用——懒分配,通俗的讲就是程序申请内存的时候,操作系统并不直接分配内存,而是只增大进程的内存空间字段值,当真正需要用到申请的内存时,因为这部分内存没有分配,所以会引发页错误中断从而陷入内核,这时候再实际分配内存并重新执行指令。这样做的原因是为进程在申请内存时,很难精确地知道所需要的内存多大,因此,进程倾向于申请多于所需要的内存。这样会导致一个问题:有些内存可能一直不会使用,申请了很多内存但是使用的很少,从而造成浪费。
xv6的进程的地址空间是从0~MAXVA连续的,其分布如下:
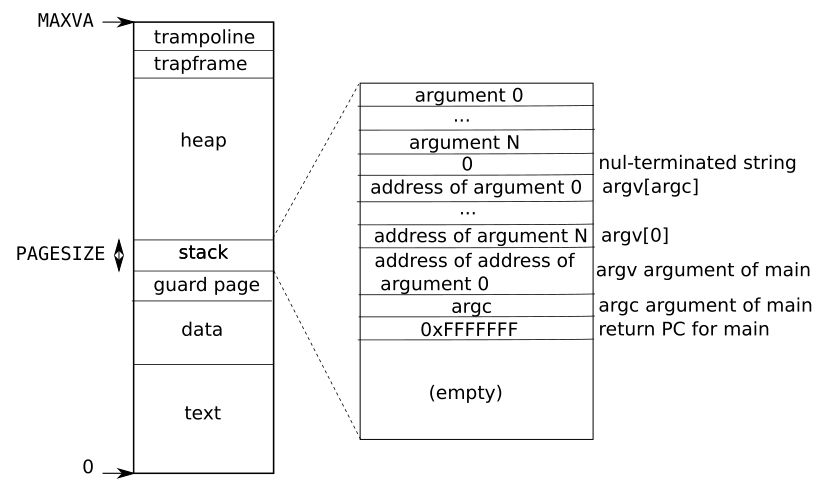
进程创建时,首先为可执行程序分配代码段(text)和数据段(data),然后分配一个无效的页 guard page 用于防止栈溢出。接下来分配进程用户空间栈,xv6 栈的大小是4096,刚好对应一页内存。值得注意的是,栈的生长方向是向下的,sp 是栈指针,初始时指向栈底,即大的地址位置。在栈生长时,栈指针(sp)减小。栈的上面是堆(heap),堆的大小是动态分配的,进程初始化时,堆大小为 0,p->sz 指针指向栈底位置。
本实验的前置知识是xv6 book的第 4 章(特别是 4.6),以及阅读相关的源码,比如kernel/trap.c,kernel\vm.c,kernel/sysproc.c。
Eliminate allocation from sbrk()
这部分任务的主要工作就是取消sys_sbrk()中对growproc()的调用,改成只增加sz字段。
注意,有一些特殊情况需要处理:
- 如果参数n是小于0的,那么需要将对应的内存释放,可以仿照growproc的方法来写。
- 如果堆空间大小超过了MAXVA或者需要释放小于0的地址,那么就直接返回,不进行操作。
代码如下:
// kernel/sysproc.c
uint64
sys_sbrk(void)
{
int addr;
int n;
if(argint(0, &n) < 0)
return -1;
struct proc *p = myproc();
addr = p->sz;
if(addr + n >= MAXVA || addr + n <= 0)
return addr;
p->sz = addr + n;
// if(growproc(n) < 0)
// return -1;
if(n < 0){
uvmdealloc(p->pagetable, addr , p->sz);
}
return addr;
}Lazy allocation
首先根据上一个实验的经验和任务提示,我们需要去usertrap()中添加一些处理的函数,而且页错误的错误码是13或15,可以通过r_scause()来查看错误码,r_stval()来获取导致页错误的虚拟地址,再直接仿照uvmalloc()的写法申请内存,需要注意的是,如果内存申请成功之后发现虚拟地址不合法,需要把申请的内存释放掉,比如va >= p-sz,虚拟地址超过了堆实际分配的大小,或者是没有成功映射到物理地址等等,一旦出现这些情况需要把进程kill掉。此外,我们还需要判断栈溢出,p->trapframe->sp 是指栈指针的位置,所以 PGROUNDDOWN(p->trapframe->sp) 是指栈顶最大值,是 guard 页的最大地址,一旦va比栈顶最大值小说明溢出,也同上处理。代码如下:
// in kernel/trap.c usertrap()
else if(r_scause() == 13 || r_scause() == 15) {
uint64 va = r_stval();
uint64 pa = (uint64)kalloc();
if (pa == 0) {
p->killed = 1;
} else if (va >= p->sz || va <= PGROUNDDOWN(p->trapframe->sp)) {
kfree((void*)pa);
p->killed = 1;
} else {
va = PGROUNDDOWN(va);
memset((void*)pa, 0, PGSIZE);
if (mappages(p->pagetable, va, PGSIZE, pa, PTE_W | PTE_U | PTE_R) != 0) {
kfree((void*)pa);
p->killed = 1;
}
}
}任务提示告诉我们uvmunmap()会panic,所以我们还需要进去把它改成continue。
// kernel/vm.c
void
uvmunmap(pagetable_t pagetable, uint64 va, uint64 npages, int do_free)
{
uint64 a;
pte_t *pte;
if((va % PGSIZE) != 0)
panic("uvmunmap: not aligned");
for(a = va; a < va + npages*PGSIZE; a += PGSIZE){
if((pte = walk(pagetable, a, 0)) == 0)
//panic("uvmunmap: walk");
continue;
if((*pte & PTE_V) == 0)
continue;
//panic("uvmunmap: not mapped");
if(PTE_FLAGS(*pte) == PTE_V)
panic("uvmunmap: not a leaf");
if(do_free){
uint64 pa = PTE2PA(*pte);
kfree((void*)pa);
}
*pte = 0;
}
}这样任务二就完成了,执行echo hi不会报错。
Lazytests and Usertests
最后是要通过整个的测试,其实就是需要处理两个函数因为缺页导致的panic,uvmcopy()和walkaddr()
fork 函数在创建进程时会调用 uvmcopy 函数。由于没有实际分配内存而引起panic,所以直接忽略 pte 无效,继续执行代码。
// kernel/vm.c
int
uvmcopy(pagetable_t old, pagetable_t new, uint64 sz)
{
pte_t *pte;
uint64 pa, i;
uint flags;
char *mem;
for(i = 0; i < sz; i += PGSIZE){
if((pte = walk(old, i, 0)) == 0)
continue;
//panic("uvmcopy: pte should exist");
if((*pte & PTE_V) == 0)
continue;
//panic("uvmcopy: page not present");
pa = PTE2PA(*pte);
flags = PTE_FLAGS(*pte);
if((mem = kalloc()) == 0)
goto err;
memmove(mem, (char*)pa, PGSIZE);
if(mappages(new, i, PGSIZE, (uint64)mem, flags) != 0){
kfree(mem);
goto err;
}
}
return 0;
err:
uvmunmap(new, 0, i / PGSIZE, 1);
return -1;
}当执行read/write 等系统调用时,由于进程已经陷入内核,页表会切换为内核页表,无法直接访问虚拟地址。walkaddr()的作用就是将虚拟地址翻译为物理地址。这里如果没找到对应的物理地址,就分配一个,注意判断地址无效,和任务二中基本等同。
// kernel/vm.c
uint64
walkaddr(pagetable_t pagetable, uint64 va)
{
pte_t *pte;
uint64 pa;
if(va >= MAXVA)
return 0;
pte = walk(pagetable, va, 0);
//if(pte == 0)
// return 0;
//if((*pte & PTE_V) == 0)
// return 0;
if (pte == 0 || (*pte & PTE_V) == 0) {
//pa = lazyalloc(va);
struct proc *p = myproc();
if(va >= p->sz || va < PGROUNDUP(p->trapframe->sp)) return 0;
pa = (uint64)kalloc();
if (pa == 0) return 0;
if (mappages(p->pagetable, va, PGSIZE, pa, PTE_W|PTE_R|PTE_U|PTE_X) != 0) {
kfree((void*)pa);
return 0;
}
return pa;
}
if((*pte & PTE_U) == 0)
return 0;
pa = PTE2PA(*pte);
return pa;
}至此就完成了整个Lab。
总结
这个实验不算太难,但是小细节,比如判断虚拟地址无效的地方比较多。通过这个实验也能深入了解一下懒分配的机制。

